An Analysis of ICP Variants
Over the years, various ICP modifications have been proposed. Now, which one should you use?...
2021, Mar 30 — 6 minute readNow we verify the performance of MMSE estimator using the following MATLAB Code.
Hi there! I’m Danielle Navarro. I’m adata scientist,generative artist, and arecovering academic living in Sydney with my two kids and a Netflix subscription. Once upon a time I was a mathematical psychologist. After that I was developer advocate and occasional software engineer. I’ve sometimes been accused of being a statistician.
Hi there! I’m Yihui Xie. I’m aFreelancer (open source programmer, contractor, blogger, and writer)
on Mastodon and Blu Esky
Hi there! I’m Prof Richard Xu.I am a Professor at the Department of Mathematics, Hong Kong Baptist University (HKBU) 香港浸会大学数学系教授
Hi there! I’m Alexander Fischer.Data Scientist @trivago
Hi there! I’m Ross Wightman.Computer Vision @huggingface. Always learning, constantly curious. Building ML/AI systems, watching loss curves.
Hi there! I’m Yixuan Qiu. Currently an associate professor inSchool of Statistics and Management atShanghai University of Finance and Economics (SUFE).
ABP offers an opinionated architecture to build enterprise software solutions with best practices on top of the .NET and the ASP.NET Core platforms.
Hi there! I’m Ross Wightman.
Rotation_related_problems. Quarternions. Rodrigues’ rotation formula
There are already a fair number of books about Numpy (see Bibliography) and a legitimate question is to wonder if another book is really necessary. As you may have guessed by reading these lines, my personal answer is yes, mostly because I think there is room for a different approach concentrating on the migration from Python to Numpy through vectorization.
Binary IQ — A model of LLM capability
Lightweight property-based testing at Row Zero — How we verify correctness
Rust Macros: Zero to Hero — A comprehensive guide on Rust macros
Algorithms we develop software by — Pathfinding applied to the software solution domain
Building Filesystems — High level ideas in filesystem design
Quasirandom sequences — Cool method to generate non-clumping random points
Hi, I'm Charlie Marsh.
I'm building high-performance developer tools for Python, starting with Ruff, an extremely fast Python linter written in Rust.
I was most recently a staff software engineer at Spring Discovery. Before that, I was a senior software engineer at Khan Academy.
This is a collection of notes and blog posts I’ve written on Notion:
You can find me on Twitter.
For older posts and projects, check out my personal site.
Hey, I'm Kevin. I am a PhD student at BAIRadvised by Pieter Abbeel andSergey Levine. I did my B.S. and M.Eng at MIT with Phillip Isola. I am interested in deep reinforcement learning, unsupervised learning, and AI-based creative tools. I also lead engineering at ParagraphAI. I have spent time atCross Labs, Sizigi,Autodesk Research, and OpenAI. In my free time, I like to design and build video games.

Intersection-over-union (IoU), also known as the Jaccard index, is a commonly used measure for determining how accurate a proposed image segmentation is, compared to a known/ground-truth segmentation. In segmentation tasks the IoU is prefered over accuracy as it is not as affected by the class imblances that are inherent in foreground/background segmentation tasks. As an example, if a ground truth image is made up of 90% background pixels, a proposed segmentation that classifies all pixels as background will have an accuracy of 90% whereas it would have an IoU of 0%.
Published:
Published:
This code in this repository can be used to reproduce the ImageNet validation results for Keras pretrained models. A blog post describing this process in more detail is here.
.npy files) that can be used “as is” with pre-trained Keras models| Scarlet2 – Thoughts for a major redesign Astronomical source modeling and separation, all new and shiny |
| Bayesian inference three ways Running MCMC, Hamiltonian MC, and simulation-based inference with a few lines of code |
This is a collection of numpy exercises from numpy mailing list, stack overflow, and numpy documentation. I've also created some problems myself to reach the 100 limit. The goal of this collection is to offer a quick reference for both old and new users but also to provide a set of exercises for those who teach. For extended exercises, make sure to read From Python to NumPy.
There are already a fair number of books about Numpy (see Bibliography) and a legitimate question is to wonder if another book is really necessary. As you may have guessed by reading these lines, my personal answer is yes, mostly because I think there is room for a different approach concentrating on the migration from Python to Numpy through vectorization. There are a lot of techniques that you don't find in books and such techniques are mostly learned through experience. The goal of this book is to explain some of these techniques and to provide an opportunity for making this experience in the process.
Website: http://www.labri.fr/perso/nrougier/from-python-to-numpy
Table of Contents
I am Heinrich 'Heiner' Küttler. I am a member of the technical team at xAI. Previously, I was the LLM Infra Lead and a member of the founding team at Inflection AI.WebuiltLLMs. Before this, was a Research Engineering Manager at Meta AI Research in London, leading Reinforcement Learning engineering across EMEA, and before that I was a Senior Research Engineer and Team Lead atDeepMind, working on projects like DMLab, StarCraft, and AGI. I also once was a Technical Solutions Consultant at Google in London. I received my PhD in Mathematical Physics fromLMU Munich in 2014.
If you have taken a probability or statistics course, you probably (ha!) know about probability density functions (pdfs). A pdf is a positive function that we use as a density and to make it aprobabilty density it needs to integrate to one. If
Over the years, various ICP modifications have been proposed. Now, which one should you use?...
2021, Mar 30 — 6 minute readAfter having focused on GANs exclusively for the last year and a half, I wanted...
2020, Dec 30 — 7 minute readThe ICP algorithm consists of the following five steps: source point selection, correspondence search, correspondence weighting, correspondence rejection, and the minimization of an error metric. Source point selection and correspondence weighting are by default differentiable, so it is the remaining three steps that we need to explore in more detail.
Standard ICP correspondences are found by searching the nearest neighbor of each source point within the target point cloud, which can be formulated as follows:
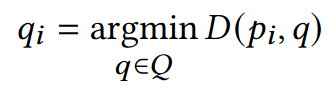
The problem here is that the argmin operation is not properly differentiable, since its derivative is everywhere either 0 or undefined. There exist a variety of approximate methods, but they are similarly based on concrete selections and are, therefore, not differentiable either.
Fortunately, a soft relaxation can be formulated by expressing correspondence points as linear combinations of all target points with weights calculated as the softmax over negative distances:
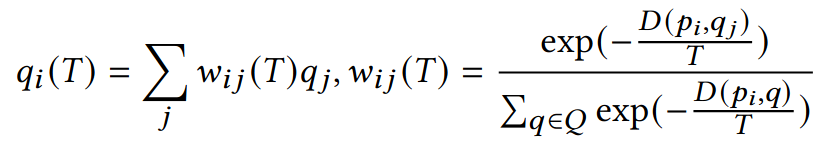
Software developer and Open Source nut. Creator of the Flask framework. Engineering at@getsentry. Other things of interest:@palletsand@rust-lang
Some tips for how to be more productive in Rust by avoiding situations you cannot solve in Rust.
A little confession that I have no idea how asyncio works in Python 3.
asyncio is supposed to implement asynchronous IO with the help of coroutines. Originally implemented as a library around the yield andyield from expressions it's now a much more complex beast as the language evolved at the same time. So here is the current set of things that you need to know exist:
In addition the language gained a few special methods that are new:
Some hidden features of the Python re module and the support machinery that drives it.
There are many terrible modules in the Python standard library, but the Python re module is not one of them. While it's old and has not been updated in many years, it's one of the best of all dynamic languages I would argue.
One annoying thing is that our group indexes are not local to our own regular expression but to the combined one. This means if you have a rule likeand you want to access that group by index, it will be wrong. This would require a bit of extra engineering with a class that wraps the SRE match object with a custom one that adjusts the indexes and group names. If you are curious about that I made a more complex version of the above solution that implements a proper match wrapper in a github repository together with some samples of what you can do with it.
For the past two years, I’ve been quite heavily invested inTensorFlow, either writing papers about it, givingtalks on how to extend its backend or using it for my own deep learning research. As part of this journey, I’ve gotten quite a good sense of both TensorFlow’s strong points as well as weaknesses – or simply architectural decisions – that leave room for competition. That said, I have recently joined the PyTorch team at Facebook AI Research (FAIR), arguably TensorFlow’s biggest competitor to date, and currently much favored in the research community for reasons that will become apparent in subsequent paragraphs.
No NameFYI: this idea of constructing a computation graph at runtime was done by Acar at CMU for self adjusting computations. You might be able to steal some ideas from them.
I’m an experienced Data Scientist with specialized skills in machine learning-based solutions. I enjoy staying on top of cutting-edge data technologies, including big data platforms, deep learning, optimization methods, and business analytics. My current work involves building data-driven products to enable smarter recommendations for Microsoft Partners, M365 service administrators and end-users to ensure the best usage of M365 services. Before that, I have experience working in various verticals like agricultural technology, pharmaceuticals, retail, e-commerce, and ride-sharing business model.
Edward Z. Yang is a research engineer at Facebook who works on PyTorch, an open source deep learning library. In a previous life, he worked on Backpack, a new module system for Haskell.
You can find more outdated information about me at http://ezyang.com.
Realcat Vincentqyw(https://github.com/Vincentqyw) starred a repository on 13/5/25
ngxson/smolvlm-realtime-webcam (HTML) 3.2k STARS
Realcat Vincentqyw(https://github.com/Vincentqyw) starred a repository on 7/5/25
huggingface/nanoVLM (Jupyter Notebook 79.9%, Python 20.1%) 961 STARS
andimarafioti Andrés Marafioti
51 repositories236 followers
follows
andimarafioti Oriol Nieto
52 repositories226 followers
Realcat Vincentqyw(https://github.com/Vincentqyw) starred a repository on 3/5/25
skyzh/tiny-llm (Python, C++) 1.8k STARS
I've cleaned up (somewhat) my notes from Cambridge Part III and have put them online - with LaTeX sources available onGitHub and PDFs linked below.
From t-tests to deep learning, I've covered a lot of ground in modeling, visualizing, and understanding data. I can provide inference for models on millions of observations, classify biomedical images to determine pathology, and scrape the web to explore political sentiment. What 's more, I can help others understand the results and take appropriate action regarding them.

I'm interested in exploring other ways to teach and discuss data science, machine learning, and AI. To this end, I piloted a series ofFacebook Live coding sessions at DataCamp, which saw up to 40K unique viewers. Two of my favourites areGetting Started with the Tidyverse through the Titanic data set andWeb Scraping & NLP in Python, in which I scrape novels from the web and plot word frequency distributions.
I enjoy writing tutorials. You can find a bunch I've written onDataCamp's community page by searching for my name. Here are a few to get started with:
Groupby, split-apply-combine and pandasHierarchical indices, groupby and pandasPreprocessing in Data Science (Part 1)Preprocessing in Data Science (Part 2)Preprocessing in Data Science (Part 3)
I'm constantly thinking about how data science notebook technologies can be used to design productive educational environments. You can check out Eric Ma's and my interactive Jupyter notebooks for our Bayesian data science workshopshere on Binder (more context in the GitHub repohere). I also built a DataCamp project that leverages the capabilities of Jupyter notebooks to create a novel educational experience: it's called"Word Frequency in Moby Dick" and in it, you'll get to scrape the novel Moby Dick from the website Project Gutenberg (which contains a large corpus of books), extract words from it, and dive into analyzing the distribution of words using the Natural Language Toolkit (nltk).
I've given a lot of webinars for business leaders, managers, and learning and development leaders across several verticals. Highlights include:What Managers Need To Know About Machine Learning,Inside the Data Science Workflow andData Literacy in the 21st Century.
SciPy 2018 Tutorial
This was a tutorial that I co-taught with Eric Ma to build participants' knowledge of Bayesian inference, workflows and decision making under uncertainty. We started with the basics of probability via simulation and analysis of real-world datasets, building up to an understanding of Bayes' theorem. We then introduced the use of probabilistic programming to do statistical modelling. Throughout this tutorial, we used a mixture of instructional time and hands-on time. During instructional time, we used a variety of datasets to anchor our instruction; during hands-on time, which immediately followed instructional time, our participants applied the concepts learned to the Darwin's finches dataset, which permeated the entire tutorial.
Tutorial materialPyCon 2019 Tutorial
This tutorial was an Introduction to Bayesian data science through the lens of simulation or hacker statistics. Learners became familiar with many common probability distributions through i) matching them to real-world stories & ii) simulating them. They worked with joint/conditional probabilities, Bayes Theorem, prior/posterior distributions and likelihoods, while seeing their applications in real-world data analyses. They then saw the utility of Bayesian inference in parameter estimation and comparing groups and we wrapped up with a dive into the wonderful world of probabilistic programming using PyMC3.
Tutorial materialHow to do Bayesian statistical modelling using numpy and PyMC3
Jupyter Notebook
Both lectures are available on the COSYNE YouTube channel (see lecture title links) under a Creative Commons license. To request access to the lecture slides, please email: kanaka_rajan@hms.harvard.edu & kanaka-admin@stellatecomms.com
If you 'd like to deepen your understanding of recurrent neural networks, I encourage you to complete a problem set created in collaboration with the COSYNE Tutorial TAs. The problem set has detailed instructions and questions to work through. Problems 1 and 2 are intermediate and should be done after watching Lecture 1; Problem 3 is advanced and should be done after watching Lecture 2. Solutions are available in Julia, MATLAB, and Python.
At atomsandbits.ai we implement some seriously large formulas in TensorFlow. If we just went from LaTeX to tf. we wouldn't be able to do it. Here's a list of tricks and tools we use, applied to the problem of averaging rotations. Come for the tf. stay for the hypersphere.
The tensormol0.2 model chemistry reproduces a huge swath of chemistry (37 elements), which is in some sense a large fraction of our world. It's a big ole' formula for some geometry:
How does one use TensorFlow effectively to get something complicated done? It's not easy. I thought I'd write up an example a little simpler than modeling all of chemistry. How about averaging rotations/axis systems? Simple right? Well interesting story… The math is mostly due to Hamilton (~1843), however it wasn’t until the advent of computer graphics in 1985 that people even bothered to work out how to interpolate between rotations perfectly.
#Rotation & Quaternions
The rotational algebra of our world is a beautiful bedeviling thing. The reason is that although rotations act on a three dimensional space, when embedded in three dimensions, rotations are not smooth or unique. When represented with Euler angles or matrices, every rotation has multiple representations. Change the order of rotations and you also change the endpoint (rotations are non-commutative) Traveling smoothly along some paths of rotations using a three dimensional embedding, suddenly the third degree of freedom can become inaccessible (the phenomenon of “Gimbal lock”). If you try to define an average or interpolated point-of-view in a naive way (axes=> angles => interpolated angles) you will find gibberish zero axes, and jerky non-smooth behavior.
The rotational algebra of our world is a beautiful bedeviling thing. The reason is that although rotations act on a three dimensional space, when embedded in three dimensions, rotations are not smooth or unique. When represented with Euler angles or matrices, every rotation has multiple representations. Change the order of rotations and you also change the endpoint (rotations are non-commutative) Traveling smoothly along some paths of rotations using a three dimensional embedding, suddenly the third degree of freedom can become inaccessible (the phenomenon of “Gimbal lock”). If you try to define an average or interpolated point-of-view in a naive way (axes=> angles => interpolated angles) you will find gibberish zero axes, and jerky non-smooth behavior.
To have smooth topology rotations must be embedded within a four-dimensional hypersphere, so we can forgive your brain. In this space a rotation is a 4-dimensional point, a quaternion, whose components can be thought of as the angle and 3 axis components of the rotation. Given a 3x3 rotation matrix Q, one can parameterize a quaternion (w,x,y,z)
To have smooth topology rotations must be embedded within a four-dimensional hypersphere, so we can forgive your brain. In this space a rotation is a 4-dimensional point, a quaternion, whose components can be thought of as the angle and 3 axis components of the rotation. Given a 3x3 rotation matrix Q, one can parameterize a quaternion (w,x,y,z).

Given any set of orthogonal axes (rows of Q), Euler's theorem guarantees an axis-angle rotation which can map the natural xyz axes back and forth into the new frame. The formula above yields the natural 4-d form of that rotation.
Now suppose you have two, three or four systems of axes (ax_1, ax_2, ax_3). For example you want to look at the sun then the moon, or you want to fit 4 pretty objects in your field of vision, or define invariant axes for a cloud of points (the reason we use this math in TensorMol). Can you simply average the quaternion components q_av = (ax_1+ax_2+ax_3)/3? Sadly no… You can immediately understand why if you imagine averaging rotations around opposite axis vectors as an owl might when spinning his head. The “good, smooth” quaternions keep to the surface of the 4-d hypersphere (a curvy subset of 4d-euclidean space). To interpolate lines on that sphere, you can use SLERP. To average multiple quaternions we must construct the 4x4 matrix which is the outer product of the list of quaternions (Nx4) with itself, weighted if desired:
The largest eigenvector of this matrix is the desired average quaternion.
Again, my goal is to get rotationally invariant axes for a set of points which smooth, differentiable and local. I will walk through my whole implementation of this in tf. Step 1- Don't use tf. Write a simple test of your formulas in a notebook like math interface (mathematica, ipython/sage). Verify everything is working when you use all the fancy library routines tf. doesn't have (eigenvectors etc.). Here's what that looks like using mathematica.

Those fancy manipulate sliders are a nice way to get tangible faith that the point cloud is rotationally invariant when transformed using an averaged axis system depending on points in the cloud. It remains for us to do this same thing in tf. Were' ready for step 2:
def slerp(v0, v1, t=0.05):
"""
Interpolate between quaternions v0 and v1.
"""
v0 = safe_normalize(v0)
v1 = safe_normalize(v1)
dot = tf.reduce_sum(v0*v1,axis=-1,keepdims=True)
# If the dot product is negative, slerp won't take
# the shorter path. Note that v1 and -v1 are equivalent when
# the negation is applied to all four components. Fix by
# reversing one quaternion.
signflip = tf.where(tf.less_equal(dot,0.),-1.*tf.ones_like(dot),tf.ones_like(dot))
v1 *= signflip
dot *= signflip
# Linear answer.
linq = safe_normalize(v0 + t*(v1-v0))
#
sdot = tf.clip_by_value(dot,-1.0,1.0)
theta_0 = tf.acos(sdot)
theta = theta_0*t
sin_theta = tf.sin(theta)
sin_theta_0 = tf.sin(theta_0)
s0 = tf.cos(theta) - dot * sin_theta / (sin_theta_0+1e-19)
s1 = sin_theta / (sin_theta_0+1e-19)
sq = safe_normalize((s0 * v0) + (s1 * v1))
#
DOT_THRESHOLD = 0.9995
tdot = tf.concat([dot,dot,dot,dot],axis=-1)
slerpd = tf.where(tf.greater(tdot,DOT_THRESHOLD),linq,sq)
ttiled = tf.concat([t,t,t,t],axis=-1)
slerpdorv1 = tf.where(tf.greater(ttiled,1.0-1e-14),v1,slerpd)
return tf.where(tf.less(ttiled,1e-14),v0,slerpdorv1)
def sftpluswparam(x):
return tf.log(1.0 + tf.exp(100. * x)) / 100.0
def RotToQuat(axes_):
"""
axes is a ... X 3 3 tensor of axes
this generates a ... X 4 tensor of quaternions.
which are 1:1 with those axes.
"""
w = (1./2.)*tf.sqrt(1e-15+tf.abs(1 + axes_[...,0, 0] + axes_[...,1, 1] + axes_[...,2, 2]))
x = tf.sign(axes_[...,2, 1] - axes_[...,1, 2])*tf.abs(0.5*tf.sqrt(1e-15+tf.abs(1.0 + axes_[...,0, 0] - axes_[...,1, 1] - axes_[...,2, 2])))
y = tf.sign(axes_[...,0, 2] - axes_[...,2, 0])*tf.abs(0.5*tf.sqrt(1e-15+tf.abs(1.0 - axes_[...,0, 0] + axes_[...,1, 1] - axes_[...,2, 2])))
z = tf.sign(axes_[...,1, 0] - axes_[...,0, 1])*tf.abs(0.5*tf.sqrt(1e-15+tf.abs(1.0 - axes_[...,0, 0] - axes_[...,1, 1] + axes_[...,2, 2])))
return tf.stack([w,x,y,z],axis=-1)
def QuatToRot(q):
"""
a_ ... X 4 tensor of quaternions
this generates a ... X 3 X 3 of rotation matrices.
"""
tmp=tf.stack([1 - 2.*(q[...,2]*q[...,2] + q[...,3]*q[...,3]), 2*(q[...,1]*q[...,2] - q[...,3]*q[...,0]),
2*(q[...,1]*q[...,3] + q[...,2]*q[...,0]),2*(q[...,1]*q[...,2] + q[...,3]*q[...,0]), 1 - 2.*(q[...,1]*q[...,1] + q[...,3]*q[...,3]),
2*(q[...,2]*q[...,3] - q[...,1]*q[...,0]),2*(q[...,1]*q[...,3] - q[...,2]*q[...,0]), 2*(q[...,2]*q[...,3] + q[...,1]*q[...,0]),
1 - 2.*(q[...,1]*q[...,1] + q[...,2]*q[...,2])],axis=-1)
return tf.reshape(tmp,[-1,3,3])
def VectorsToOrient(v1,v2):
v1n = safe_normalize(v1)
v2n = safe_normalize(v2)
v3 = safe_normalize(tf.cross(v1n, v2n)+tf.constant(np.array([0., 0., 1e-19]), dtype=tf.float64))
# Compute the average of v1, v2, and their projections onto the
# plane.
v_av = (v1n + v2n) / 2.0
v_av = safe_normalize(v_av)
# Rotate pi/4 cw and ccw to obtain v1,v2
first = TF_AxisAngleRotation(v3, v_av, tf.constant(-Pi / 4., dtype=tf.float64))
second = TF_AxisAngleRotation(v3, v_av,tf.constant(Pi / 4., dtype=tf.float64))
vs = tf.concat([first[:, tf.newaxis, :], second[:, tf.newaxis, :],v3[:, tf.newaxis, :]],axis=1)
return vs
def VectorsToAxisQs(v1,v2):
return tf.reshape(RotToQuat(VectorsToOrient(v1,v2)),(-1, 4))
def safe_normalize(x_):
nrm = tf.clip_by_value(tf.norm(x_,axis=-1,keepdims=True),1e-36,1e36)
nrm_ok = tf.logical_and(tf.not_equal(nrm,0.),tf.logical_not(tf.is_nan(nrm)))
safe_nrm = tf.where(nrm_ok,nrm,tf.ones_like(nrm))
return x_*tf.where(nrm_ok,1.0/safe_nrm,tf.zeros_like(nrm))
def safe_inv_norm(x_):
nrm = tf.clip_by_value(tf.norm(x_,axis=-1,keepdims=True),1e-36,1e36)
nrm_ok = tf.logical_and(tf.not_equal(nrm,0.),tf.logical_not(tf.is_nan(nrm)))
safe_nrm = tf.where(nrm_ok,nrm,tf.ones_like(nrm))
return tf.where(nrm_ok,1.0/safe_nrm,tf.zeros_like(nrm))
def safe_norm(x_):
nrm = tf.clip_by_value(tf.norm(x_, axis=-1, keepdims=True), 1e-36, 1e36)
nrm_ok = tf.logical_and(
tf.not_equal(nrm, 0.), tf.logical_not(tf.is_nan(nrm)))
safe_nrm = tf.where(nrm_ok, nrm, tf.zeros_like(nrm))
return safe_nrm
with tf.Graph().as_default():
xyzs = tf.Variable(np.random.random((batch_size,MaxNAtom,3))*7.0 - 5.0)
init = tf.global_variables_initializer()
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True))
sess.run(init)
print sess.run(xyzs[0,:2])
print sess.run(VectorsToOrient(xyzs[:,0],xyzs[:,1]))
print sess.run(RotToQuat(VectorsToOrient(xyzs[:,0],xyzs[:,1])))
print sess.run(QuatToRot(RotToQuat(VectorsToOrient(xyzs[:,0],xyzs[:,1]))))
Style notes about the tf. code given above:
So is all this serious rotational mathematics only good for defining axis systems for atomic positions. No! Facebook AI-Research and collaborators from the EPFL published a nice use of quaternions for skeletal motion planning last week
For the first three years of OpenAI, I dreamed of becoming a machine learning expert but made little progress towards that goal. Over the past nine months, I've finally made the transition to being a machine learning practitioner. It was hard but not impossible, and I think most people who are good programmers and know (or are willing to learn) the math can do it too. There are many online courses to self-study the technical side, and what turned out to be my biggest blocker was a mental barrier — getting ok with being a beginner again.

Studying machine learning during the 2018 holiday season.
A founding principle of OpenAI is that we value research and engineering equally — our goal is to build working systems that solve previously impossible tasks, so we need both. (In fact, our team is comprised of 25% people primarily using software skills, 25% primarily using machine...
A founding principle of OpenAI is that we value research and engineering equally — our goal is to build working systems that solve previously impossible tasks, so we need both. (In fact, our team is comprised of 25% people primarily using software skills, 25% primarily using machine learning skills, and 50% doing a hybrid of the two.) So from day one of OpenAI, my software skills were always in demand, and I kept procrastinating on picking up the machine learning skills I wanted.
After helping build OpenAI Gym, I was called to work on Universe. And as Universe was winding down, we decided to start working on Dota — and we needed someone to turn the game into a reinforcement learning environment before any machine learning could begin.
After we lost two games in The International in 2018, most observers thought we'd topped out what our approach could do. But we knew from our metrics that we were right on the edge of success and mostly needed more training. This meant the demands on my time had relented, and in November 2018, I felt I had an opening to take a gamble with three months of my time.
I learn best when I have something specific in mind to build. I decided to try building a chatbot. I started self-studying the curriculum we developed for our Fellows program, selecting only the NLP-relevant modules. For example, I wrote and trained an LSTM language model and then a Transformer-based one. I also read up on topics like information theory and read many papers, poring over each line until I fully absorbed it.
I learn best when I have something specific in mind to build. I decided to try building a chatbot. I started self-studying the curriculum we developed for our Fellows program, selecting only the NLP-relevant modules. For example, I wrote and trained an LSTM language model and then a Transformer-based one. I also read up on topics like information theory and read many papers, poring over each line until I fully absorbed it.
It was slow going, but this time I expected it. I didn't experience flow state. I was reminded of how I'd felt when I just started programming, and I kept thinking of how many years it had taken to achieve a feeling of mastery. I honestly wasn't confident that I would ever become good at machine learning. But I kept pushing because… well, honestly because I didn't want to be constrained to only understanding one part of my projects. I wanted to see the whole picture clearly.
It was slow going, but this time I expected it. I didn't experience flow state. I was reminded of how I'd felt when I just started programming, and I kept thinking of how many years it had taken to achieve a feeling of mastery. I honestly wasn't confident that I would ever become good at machine learning. But I kept pushing because… well, honestly because I didn't want to be constrained to only understanding one part of my projects. I wanted to see the whole picture clearly.
One important conceptual step was overcoming a barrier I'd been too timid to do with Dota: make substantive changes to someone else's machine learning code. I fine-tuned GPT-1 on chat datasets I'd found, and made a small change to add my own naive sampling code. But it became so painfully slow as I tried to generate longer messages that my frustration overwhelmed my fear, and I implemented GPU caching — a change which touched the entire model.
One important conceptual step was overcoming a barrier I'd been too timid to do with Dota: make substantive changes to someone else's machine learning code. I fine-tuned GPT-1 on chat datasets I'd found, and made a small change to add my own naive sampling code. But it became so painfully slow as I tried to generate longer messages that my frustration overwhelmed my fear, and I implemented GPU caching — a change which touched the entire model.
I had to try a few times, throwing out my changes as they exceeded the complexity I could hold in my head. By the time I got it working a few days later, I realized I'd learned something that I would have previously thought impossible: I now understood how the whole model was put together, down to small stylistic details like how the codebase elegantly handles TensorFlow variable scopes.
I had to try a few times, throwing out my changes as they exceeded the complexity I could hold in my head. By the time I got it working a few days later, I realized I'd learned something that I would have previously thought impossible: I now understood how the whole model was put together, down to small stylistic details like how the codebase elegantly handles TensorFlow variable scopes.
Binary IQ — A model of LLM capability
Lightweight property-based testing at Row Zero — How we verify correctness
Rust Macros: Zero to Hero — A comprehensive guide on Rust macros
Algorithms we develop software by — Pathfinding applied to the software solution domain
Building Filesystems — High level ideas in filesystem design
Quasirandom sequences — Cool method to generate non-clumping random points
How to write complex software — A general method
Bureaulogy — The study of bureaucracy
A peasant's plight — On the shackling of the peasantry
Every Man his own API — A sociotechnological trend
Culture is a set of social Schelling points — Solving coordination problems in community-building
Portals are Undertheorized — The importance of arrival
Binary IQ — A model of LLM capability
Designing bug-proof engines — A spectrum of engineering philosophies
Accidental Urbanism — How I got into the scene
How to Bootstrap a Town — A modest plan
Sports vs Games — An aesthetic distinction
Nobody Cares — A rant about caring
Lightweight property-based testing at Row Zero — How we verify correctness
Rust Macros: Zero to Hero — A comprehensive guide on Rust macros
Algorithms we develop software by — Pathfinding applied to the software solution domain
Status among whom? — An essay about status relativism
Ghost Side Control Escape System (BJJ) — A video instructional on my preferred side control escape system
Building Filesystems — High level ideas in filesystem design
AI follows auditability — An essay about the order AI will move through the economy
Book List — Stuff I've read
Onsen Unreality — Our experience at an onsen 'theme park' in Tokyo
Tesla Full Self-Driving — My experience with FSD
Internet Fiction — Collection of amateur stories — mainly sci-fi — that I like
All the way down — Very short story about simulation
Story Ideas — A collection of premises for stories
Things I wish I knew earlier — Collection of stuff I would tell my younger self if I could
Road Width Extremism — In favor of narrow roads
Links to See Also — Other "small web" personal sites I recommend
HTML5 Canvas simulations — A collection of little HTML5 canvas demos
Twitter — Essay about how getting on Twitter unexpectedly added a lot of value to my life
Shuttle — A useful concurrency checker library we used to verify our filesystem at AWS
Quasirandom sequences — Cool method to generate non-clumping random points
Book Review: 'The Perfectionists: How Precision Engineers Created the Modern World' — Excellent book about the history of precision machining
Markdown-ish — Writing a Markdown(ish) parser with the nom library

Honeycrisp: An Apple-First Deep Learning Framework.
Rishit DagliRishit-dagli
106 repositories891 followers
xoofx Alexandre Mutel
88 repositories1.4k followers
Alexandre Mutel (https://github.com/xoofx) starred a repository on 20/6/25
JimmyLefevre/kb (C) 275 STARS
Alexandre Mutel (https://github.com/xoofx) starred a repository on 10/5/25
metalama/Metalama (C#) 292 STARS
A meta-programming framework for code generation, aspect-oriented programming, and architecture verification of large C# codebases.
Alexandre Mutel (https://github.com/xoofx) followed a GitHub user on 2/5/25
meziantou
Alexandre Mutel (https://github.com/xoofx) starred a repository on 7/4/25
Alan-Rock-GS/GpuScript (C#) 171 STARS
Alexandre Mutel (https://github.com/xoofx) starred a repository on 5/4/25
https://github.com/nietras/Llm.cs (C#) 49 STARS
List<IObserver<T>>.ToArray() allocations in LightweightObservableBase#18316Here are the details of a specific PR from the AvaloniaUI/Avalonia repository:
This PR is removing the List<IObserver<T>>.ToArray() allocations happening in LightweightObservableBase when Routing events are fired (e.g. whenever you move the mouse)
When profiling the memory, I noticed that when generating lots of routing events (e.g. just moving the mouse over a window) several MB of IObserver<ValueTuple<Object, RoutedEventArgs>>[] were created.
Bishal Santra Bishal Santra
103 repositories36 followers
Hi, I'm Charlie Marsh.
I'm building high-performance developer tools for Python, starting with Ruff, an extremely fast Python linter written in Rust.
I was most recently a staff software engineer at Spring Discovery. Before that, I was a senior software engineer at Khan Academy.
This is a collection of notes and blog posts I’ve written on Notion:
You can find me on Twitter.
For older posts and projects, check out my personal site.
Hey, I'm Kevin. I am a PhD student at BAIRadvised by Pieter Abbeel andSergey Levine. I did my B.S. and M.Eng at MIT with Phillip Isola. I am interested in deep reinforcement learning, unsupervised learning, and AI-based creative tools. I also lead engineering at ParagraphAI. I have spent time atCross Labs, Sizigi,Autodesk Research, and OpenAI. In my free time, I like to design and build video games.
Stathis Kamperis Stathis Kamperis
15 repositories29 followers
11/2024: I won't be attending EMNLP or NeurIPS this year, but my co-authors will be presenting our work! Check out our papers onBenchmarking the Reproduction of Copyrighted Text(EMNLP Main, NeurIPS Regulatable ML Workshop Contributed Talk),Scaling a Datastore in Retrieval-Based LMs(NeurIPS Main), andAn Open Mixture-of-Experts LM(NeurIPS Workshop on Efficient Natural Language and Speech Processing (ENLSP), Oral Talk).
11/2024: I am recruiting PhD students at UC Berkeley's EECS!If you're interested, please apply directly through the UC Berkeley admissions portal (details here). Kindly note that I cannot discuss applications outside the official admissions process.
12/2023: I am attending EMNLP and NeurIPS! At EMNLP, I will give an invited talk on Rethinking the Role of Demonstrations at the Big Picture Workshop on Dec 7th, and give an oral talk on FActScore on Dec 8th. At NeurIPS, I will give a spotlight talk on SILO at the Distribution Shifts Workshop on Dec 15th, and give an oral talk on SILO at the Regulatable ML Workshop on Dec 16th.
08/2023: Together with Suchin Gururangan, we present SILO, proposing to segregate the training data and the inference-time data in nonparametric LMs to mitigate legal risk in LMs.
07/2023: Our paper that examines the role of demonstrations in CoT prompting, led by Boshi Wang, won an Honorable Mention at ACL 2023.
07/2023: I co-taught a tutorial on retrieval-based LMs at ACL 2023. Slides & recordings are available on the website.
12/2022: Check out our new preprint,Nonparametric Masked Language Modeling. Code and model checkpoints available here.
09/2022: I was selected by the EECS Rising Stars Program.
08/2022: Together with Sang Michael Xie, we wrote a post on How does in-context learning work? A framework for understanding the differences from traditional supervised learning at Stanford AI Blog.
05/2022: I co-taught the ACL tutorial on Few-Shot NLP with Pretrained Language Models (slides, recordings).
02/2022: Check out our new preprint, Rethinking the Role of Demonstrations: What makes In-context Learning Work?All experiments reproducible from this code. (Update 10/2022: The paper was accepted to EMNLP 2022.)
02/2022: I am co-organizing two workshops at ACL 2022: Repl4NLP (CFP) andSpa-NLP (CFP).
10/2021: Our new preprint, MetaICL: Learning to Learn In Context is out (w/ code). Check out the demo! (Update 04/2022: The paper was accepted to NAACL 2022.)
08/2021: Our new preprint, Noisy Channel Language Model Prompting for Few-Shot Text Classification is out w/ code! (Update 02/2022: The paper was accepted to ACL 2022.)
07/2021: Our new preprint, FaVIQ: FAct Verification from Information-seeking Questions is out! Visit FaVIQ website to download data and see samples. (Update 02/2022: The paper was accepted to ACL 2022.)
07/2021: I am co-organizing The 2nd Workshop on Unstructured/Structured KBs, hosted at AKBC 2021.
06/2021: I co-taught the NAACL-HLT tutorial on Beyond Paragraphs: NLP for Long Sequences.
04/2021: Our new preprint, Joint Passage Ranking for Diverse Multi-Answer Retrievalis out! This is done as part of my internship at Google. (Update 08/2021: The paper was accepted to EMNLP.)
01/2021: We, the NeurIPS 2020 EfficientQA organizers, together with participants, wrote NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned. The video of the NeuIPS event is also available here. (Update 05/2021: The paper was accepted to PMLR.)
12/2020: I am co-organizing The 3rd Workshop on Machine Reading for Question Answering, hosted at EMNLP 2021. Stay tuned for Call for papers!
09/2020: I made an Open-domain QA Demo using DPR. Give it a try!
06/2020: I am co-organizing Competition on Efficient Open-Domain Question Answering, hosted at NeurIPS 2020. [leaderboard]
06/2020: I am co-organizing Workshop on Unstructured/Structured KBs, hosted at AKBC 2020.
04/2020: Our new preprint, AmbigQA: Answering Ambiguous Open-domain Questionsis out! Visit AmbigQA website to download data and see samples.
04/2020: Our new preprint, Dense Passage Retrieval for Open-domain Question Answeringis out (w/ code)!
Short guide on SIMD and how to call (SIMD) intrinsics in the Julia programming language.
Analysis and optimization of a small code snippet posted on the Julia discourse mailing list.
Here are some of the open source projects I have created or been involved with:
Hi there! I’m Danielle Navarro. I’m adata scientist,generative artist, and a recovering academic living in Sydney with my two kids and a Netflix subscription. Once upon a time I was a mathematical psychologist. After that I was developer advocate and occasional software engineer. I’ve sometimes been accused of being a statistician.
djnavarro Danielle Navarro
233 repositories1.1k followers
A blog by Danielle Navarro
Hi there! I’m Danielle Navarro.
Hi there! I’m Yihui Xie. I’m a Freelancer (open source programmer, contractor, blogger, and writer)
I’m currently a freelancer, and was a software engineer at Posit Software, PBC (2013-2023). I earned my PhD from the Department of Statistics, Iowa State University. My thesis was DynamicGraphics and Reporting for Statistics, advised by Di Cook and Heike Hofmann. I have developed a series of R packages either seriously or forfun (or both), such aslitedown, knitr, animation,bookdown,blogdown,pagedown,xaringan, and tinytex. I founded a Chinese website called “Capital of Statistics” in 2006, which has grown into a large online community on statistics. I initiated the China R conference in 2008. I’m a big fan ofGitHub, LyX andPandoc. I used to hate IE but no longer care since it has almost died. I fall asleep when I see beamer slides, and I yell at people who use \textbf to write \title. I know I cannot eat code, so I cook almost every day to stay away from my computer for two hours.
Author: Yihui Xie
I was introduced to this Author by this Mastodon post -hachyderm.io/@djnavarro/113477662963181887
by the Authorhachyderm.io/@djnavarro
yihui Yihui Xie
Hi there! I’m Yihui Xie. I’m a Freelancer (open source programmer, contractor, blogger, and writer)
89 repositories9.6k followers
I got this tweet: Thomas Lumley on X: "Blog post, software, and preprint for my #JSM2018 talk/poster"
from this Author: Yihui Xie
from his blog post: Solving Statistical Computing Problems with SQL - Yihui Xie | 谢益辉
Hi there! I’m Prof Richard Xu. I’m a I am a Professor at the Department of Mathematics, Hong Kong Baptist University (HKBU) 香港浸会大学数学系教授
roboticcam Prof Richard Xu 徐亦达教授
13 repositories5.1k followers
My continuously updated Machine Learning, Probabilistic Models and Deep Learning notes and demos (2000+ slides) 我不间断更新的机器学习,概率模型和深度学习的讲义(2000+页)和视频链接
Jupyter Notebook
Hi there! I’m Ross Wightman.Computer Vision @huggingface. Always learning, constantly curious. Building ML/AI systems, watching loss curves.
rwightman Ross Wightman
74 repositories6.7k followers
milescranmer Miles Cranmer
253 repositories1.6k followers
Here are the details of a specific commit from the PySR repository:
Pull Request Test Coverage Report given in #845
Here are the details of a specific commit from the JuliaNLSolvers/Optim.jl repository:
Pull Request Test Coverage Report given in #1084
This creates a simple benchmark for catching performance regressions on small, tightly controlled problems. To kick things off I added the multivariate first-order optimizers includingAdam,AdaMax,BFGS,LBFGS,NGMRES,ConjugateGradient,GradientDescent, and MomentumGradientDescent.
I also add a GitHub action to run AirspeedVelocity.jl on this benchmark for any new PR. It will automatically print out the performance and load time comparison of master in a GitHub comment on the PR.
hey, it works :) https://github.com/JuliaNLSolvers/Optim.jl/actions/runs/14055921576/job/39355263452?pr=1138
hamelsmu HamelHusain
373 repositories2.1k followers
cderv Christophe Dervieux
321 repositories578 followers
DavisVaughan DavisVaughan
452 repositories826 followers
rwightman Ross Wightman
74 repositories6.7k followers
rwightman JonShlens
1 repository86 followers
These tutorials provide a general introduction to topics I find quite interesting but often lack good explanations in textbooks or the online literature.
A complete introduction and discussion of independent component analysis. Builds on previous tutorial on principal component analysis.
Version 1.0
A full introduction, description, derivation, and discussion of principal component analysis. Concrete examples for intuition building, the mathematical relation to SVD, and new extensions of this algorithm.
Version 3.02
A light discussion of the underlying assumptions behind entropy followed by a rigorous but simple derivation of the formula for entropy.
Version 1.01
An intuitive discussion about where Kullback-Leibler divergence arises and its relationship to likelihood theory.
Version 1.01
An introduction to the application of GLMs to model neurons and networks of neurons. Brief discussion and derivation of primary equations pertaining to maximum likelihood estimation.
Version 1.51
Hi there! I’m Yixuan Qiu. Currently an associate professor inSchool of Statistics and Management atShanghai University of Finance and Economics (SUFE).
djnavarro Danielle Navarro
233 repositories1.1k followers
yihui Yihui Xie
Hi there! I’m Yihui Xie. I’m a Freelancer (open source programmer, contractor, blogger, and writer)
89 repositories9.6k followers
yihui Yihui Xie
Hi there! I’m Yihui Xie. I’m a Freelancer (open source programmer, contractor, blogger, and writer)
89 repositories9.6k followers
yixuan Yixuan Qiu
96 repositories841 followers
stevengj Steven G. Johnson
152 repositories1.3k followers
Here are the details of the commit for this JuliaMath/FastChebInterp.jl repository:
https://discourse.julialang.org/t/multivariate-polynomial-regression-of-discrete-data-in-l-infinity-norm/125369/7?u=stevengj
https://gitlab.com/nsajko/FindMinimaxPolynomial.jl
https://xn--2-umb.com/22/approximation/
Overview of commits/PRs from July 1, 2023 to July 31, 2023I found another paper on Sattolo's algorithm that defines cyclic permutations in a different way, which allows the identity permutation only for n=1:
AutoModel class for image-text-to-text models#32042Who should be a maintainer? Somebody with GitHub Actions experience, or the desire to obtain that experience. Also a maintainer should be a modern code craftsperson that is passionate about shipping production-quality software. This GitHub Action can be part of important build and deployment pipelines. Not to mention, it is likely running inside many existing users' environments in their runners. It is important that changes are well-tested, and are the right thing for our users.
Manual Approval in a GitHub Actions Workflow
Posted: March 28, 2022
Updated: March 28, 2022
Visit the full article here
LLamaSharp is a C# wrapper around llama.cpp. This is not my project alone, but I became one of the lead maintainers last year and I've continued working on it this year.
In 2024 my major contribution to LLamaSharp was the development of the BatchedExecutor which is an entirely new low-level abstraction around language models. The BatchedExecutor is designed to expose all of the power of llama.cpp in a safe way, for example multiple parallel sequences evaluated all together in one batch is as simple as:
Sequences can be easily saved and loaded, forked into 2 sequences with the same prefix (which internally share the same space in memory), the KV cache can be accessed and manipulated (e.g. to implement context shifting), sequences can even be prompted with embeddings directly which allows things like LLava.
My long term goal for 2025 is to rewrite many of the higher level parts of LLamaSharp to operate on top of the BatchedExecutor, this will reduce the overall complexity of the project by implementing it all in one place and should offer more power to advanced users since they can always build on top of BatchedExecutor instead of using the low level llama.cpp primitives.
Martin Evans (https://github.com/martindevans) starred a repository on 5/4/25
https://github.com/MerlinVR/UdonSharp (C#) 706 STARS
momo-the-monster Momo the Monster
80 repositories50 followers
pixeljetstream Christoph Kubisch
16 repositories89 followers
Next to the white papers mentioned at the beginning, the article series"A trip through the graphics-pipeline"by Fabian Giesen is worth a read and there is also aquite in-depth talk
Visit the Blog: The ryg blog (When I grow up I'll be an inventor)Martin Evans (https://github.com/martindevans) starred a repository on 5/4/25
https://github.com/nietras/Llm.cs (C#) 49 STARS
Philipp Wagner (https://github.com/bytefish) followed Cédric Luthi (https://github.com/0xced) on 25/1/25.
Visit the @0xced/114309797988146204 post page on Hachyderm, which references the relevant issue on GitHubServiceBusAdministrationClient support #17. The posted date is 10/4/25.
In the discussion onGitHub Link - https://github.com/Azure/azure-service-bus-emulator-installer/issues/17#issuecomment-2790842139, a user expressed difficulties encountered while attempting to install and run the Azure Service Bus Emulator. They reported persistent errors that persisted despite following the provided installation instructions. The community responded with suggestions to verify system requirements and permissions, encouraging further dialogue to troubleshoot and resolve these issues collaboratively.
This source code distribution is a companion to the AWS Lambda in Action book available from Manning Publications.
JavaScript
by Danilo Poccia on 16 JUN 2020 in Amazon Elastic File System (EFS), Announcements, AWS Lambda, Compute, Launch, News, Serverless, Storage
Visit the New – A Shared File System for Your Lambda Functions Blog Postby Fei Peng on 2019-03-03 in .NET Core, SIMD, x86
Visit the Hardware Intrinsic in .NET Core 3.0 - Introduction DocumentationRepository: github.com/dotnet/runtime
Visit the GitHub Issue for API Proposal: Add Intel Hardware Intrinsic Functions and NamespaceThe SIMD-accelereted ray tracing in C# powered by Intel hardware intrinsic of .NET Core.
C#
On April 20, 2025, a Reddit user shared their excitement about completing their first significant AI project in C#, which utilized ONNX (Open Neural Network Exchange). They expressed how impressed they were by the capabilities of the ONNX framework, highlighting its ability to streamline model training and deployment across various platforms. The post detailed their journey through the project, including the challenges they faced and the solutions they discovered. The author encouraged others in the community to explore ONNX for their own AI endeavors, noting its versatility and the positive impact it had on their workflow. The enthusiasm radiating from their experience resonated with fellow enthusiasts, sparking discussions and sharing of similar projects.Link to the post - Posted on 20/4/25.
https://www.reddit.com/r/csharp/comments/1k37gj7/my_first_big_ai_project_in_c_onnx_blown_away_by/
My biggest tip is to do as much as possible on the GPU—I use ILGPU to do this, but you could also use something like compute shaders in Silk.NET, OpenTK, or ComputeSharp. — nullandkale, posted on 21/4/25
I searched in Microsoft Bing Browser with the query "ilgpu c#" and found these helpful results:Computing the Convex Hull on GPU andVectorized Computations and SIMD.
Basically all face recognition algorithms are the combination of a feature extractionand a classifier. The Eigenfaces method for example is a Principal Component Analysis with a Nearest Neighbor classifier. Local Binary Patterns Histograms . The feature (which must be an AbstractFeature) and the classifier (which must be an AbstractClassifier) form a PredictableModel, which does the feature extraction and learns the classifier.
Elasticsearch is an open source distributed, RESTful search and analytics engine, scalable data store, and vector database capable of addressing a growing number of use cases. As the heart of the Elastic Stack, it centrally stores your data for lightning-fast search, fine‑tuned relevancy, and powerful analytics that scale with ease.
Hi there! I’m ItamarSyn-Hershko.CTO & Founder of BigData Boutique. Search, BigData and Cloud expert - making the cloud a better place day by day.
Category: ASP.NET Core, DevOps, Logging, Docker
Published on: June 20, 2018
Estimated Reading Time: ~7 min read
Visit the full article: Writing Logs to Elasticsearch with Fluentd using Serilog in ASP.NET Corehttps://blog.tonysneed.com/2020/06/25/event-stream-processing-micro-framework-apache-kafka/
Category: Elasticsearch, .NET, Tutorial
Published on: 8 September 2017
Author: Ivan Cesar
Visit the full article: An Elasticsearch Tutorial for .NET DevelopersThis is an example of how Elastic Search can be integrated easily with .NET application. Feel free to fork/comment if you like.
C#
Hi there! I’m ItamarSyn-Hershko.CTO & Founder of BigData Boutique. Search, BigData and Cloud expert - making the cloud a better place day by day.
A number of articles have been written over the past few days documenting the various methods of securing Elasticsearch, most notably of which is this piece by Itamar Dyn-Hershko. For all our readers using Elasticsearch — especially those who are using it in production — who are not necessarily aware of the various pitfalls that need to be taken into consideration, we’ve summed up some of the methods that we recommend employing.
Anshuman Mishra (@mishradotexe)
I wrote Qwen 2.5 from scratch. Works with JAX, PyTorch and Tensorflow. This marks my return to open source after an year.
View the TweetCommit: checkpoint conversion wip
New File Added: tools/checkpoint_conversion/convert_qwen_checkpoints.py
Now, see another PR by the same Keras Team: SIMILAR TASK
Here are the details of a specific PR from the keras-team/keras-hub repository:
Sam Grey Danus (https://github.com/greydanus) starred 2 repositories on 02/4/25
https://github.com/zwimpee/cursivetransformer (Jupyter Notebook) 3 Stars
https://github.com/zwimpee2/cursivetransformer (Jupyter Notebook) 1 Star
Both repositories, https://github.com/zwimpee/cursivetransformer and https://github.com/zwimpee2/cursivetransformer, focus on training a transformer model to generate cursive, with progress updates noted in their respective README files (February 12, 2025, and August 13, 2025).
timdeschryver (https://github.com/timdeschryver) starred 2 repositories on 25/3/25
practical-otel/opentelemetry-aspire-collector (C#) 28 STARS
microsoft/playwright-mcp
Visit the article "Building a Secure OpenTelemetry Collector" published on 20 December, 2023 here: Building a Secure OpenTelemetry Collector
Hi there! I’m ABP.ABP
ABP offers an opinionated architecture to build enterprise software solutions with best practices on top of the .NET and the ASP.NET Core platforms.
Alexandre Mutel (https://github.com/xoofx) starred a repository on 25/3/25
abpframework/abp (C#) 13.3k STARS
ABP offers an opinionated architecture to build enterprise software solutions with best practices on top of the .NET and the ASP.NET Core platforms. It provides the fundamental infrastructure, production-ready startup templates, pre-built application modules, UI themes, tooling, guides and documentation to implement that architecture properly and automate the details and repetitive works as much as possible.
Reviewed on: December 17, 2024
Check out the GitHub Profile of CaptainSafia on GitHub.
Here are the details of a specific commit from the dotnet/aspnetcore repository:
October 2, 2011 | Programming, R, Statistics
Visit the original article on Statr.me(https://statr.me/2011/10/large-regression/).
Xiao Nan yixuanq 12 years ago: Yup. There's more. Prof. Roger Koenker once combined MySQL with his qr: Link. There's barely few experiments on the cluster & classification's hpc topic. I think the algorithms are just naturally inefficient or too complicated to reimplement.
Statistical Analysis of Large Datasets - An Exploration of R - MySQL Interface:Visit the link by Roger Koenker, University of Illinois, and Álvaro A. Novo, University of Illinois. Topics include Least Squares and Quantile Regression.
Conformal Quantile Regression pdf
Here are the details of a specific commit from the SciML/SciMLSensitivity.jl repository:
DataLoader from MLUtils https://lux.csail.mit.edu/stable/tutorials/intermediate/1_NeuralODE#Loading-MNIST
https://github.com/yunjey/pytorch-tutorial
This page has all the details of the work, which include:
https://github.com/JackHopkins/factorio-learning-environment
Recommended for you:
jump-dev/MathOptInterface.jl (https://github.com/jump-dev/MathOptInterface.jl) is a data structure for mathematical optimization problems in Julia.
MathOptInterface.jl (Julia) 434 Stars
Contributors:View Contributors
Here are the details of a specific PR from the EnzymeAD/Reactant.jl repository:
Visit the full article: Fast online estimates on the GPU | Posts · 06/08/2021 · 4 minuteshttps://blegat.github.io/teaching/
https://blegat.github.io/ccir/practical1/
Recommended for you:
jump-dev/MathOptInterface.jl (https://github.com/jump-dev/MathOptInterface.jl) is a data structure for mathematical optimization problems in Julia.
MathOptInterface.jl (Julia) 434 Stars
Contributors:View Contributors
Here are the details of a specific PR from the probabl-ai/skore repository:
Andriy Burkov (https://github.com/aburkov) starred a repository on 03/4/25
https://github.com/erikbern/ann-benchmarks (Python) 5.2k Stars
Benchmarks of approximate nearest neighbor libraries in Python
ann-benchmarks.com
"""
This module supports connecting to a PostgreSQL instance and performing vector
indexing and search using the pgvector extension. The default behavior uses
the "ann" value of PostgreSQL user name, password, and database name, as well
as the default host and port values of the psycopg driver.
"""
RUN service postgresql start && \
psql -c "CREATE USER ann WITH ENCRYPTED PASSWORD 'ann'" && \
psql -c "CREATE DATABASE ann" && \
psql -c "GRANT ALL PRIVILEGES ON DATABASE ann TO ann" && \
psql -d ann -c "GRANT ALL ON SCHEMA public TO ann" && \
psql -d ann -c "CREATE EXTENSION vector" && \
psql -c "ALTER USER ann SET maintenance_work_mem = '4GB'" && \
psql -c "ALTER USER ann SET max_parallel_maintenance_workers = 0" && \
psql -c "ALTER SYSTEM SET shared_buffers = '4GB'"
USER root
Martin Krasser(https://github.com/krasserm) starred a repository on 26/3/25
wjayesh/mahilo (Python) 360 STARS
Here are the details of the fork of this fsdl-text-recognizer-2021-labs repository:
Simon Willison(https://github.com/simonw) contributed to a repository on 14/5/25
taketwo/llm-ollama (Python) 292 STARS
Simon Willison(https://github.com/simonw) starred a repository on 3/5/25
skyzh/tiny-llm (Python, C++) 1.8k STARS
Simon Willison(https://github.com/simonw) starred a repository on 25/4/25
antirez/hnstyle (Python) 40 STARS
This repository contains the code used in the following blog post and YouTube videos:
Now, we are ready to insert the word into a Redis vector set, using the command: VADD key FP32 [blob with 350 floats] username. The details of vector sets are not covered here, but you can find the documentation here. For additional information regarding Redis, you may also check out this: Visit the full article: Reproducing Hacker News writing style fingerprinting Date: 16/4/25.
Simon Willison(https://github.com/simonw) starred a repository on 14/4/25
invisal/sqlite-internal (JavaScript, TypeScript) 260 STARS
https://github.com/querymx/querym
Simon Willison(https://github.com/simonw) starred a repository on 3/5/25
skyzh/tiny-llm (Python, C++) 1.8k STARS
Ahmet Alp Balkan(https://github.com/ahmetb) followed Anish Athalye (https://github.com/anishathalye) on 5/4/25
Ahmet Alp Balkan(https://github.com/ahmetb) starred a repository on 5/4/25
anishathalye/porcupine (Go) 1k STARS
Ahmet Alp Balkan(https://github.com/ahmetb) followed Anish Athalye (https://github.com/anishathalye) on 5/4/25
Ahmet Alp Balkan(https://github.com/ahmetb) starred a repository on 5/4/25
anishathalye/porcupine (Go) 1k STARS
Realcat Vincentqyw(https://github.com/Vincentqyw) starred a repository on 7/5/25
huggingface/nanoVLM (Jupyter Notebook 79.9%, Python 20.1%) 961 STARS
andimarafioti Andrés Marafioti
51 repositories236 followers
follows
andimarafioti Oriol Nieto
52 repositories226 followers
I've always run the basic postgres docker image with no backups or replicas configured. Since I have a new cluster now, I thought I should try something new. I recently read aboutCloudNative PG on HN so I decided to look into it. It got high praise from the replies, which is quite remarkable for HN.
It seems to have all the features I would want from a 'managed' postgres:
Realcat Vincentqyw(https://github.com/Vincentqyw) starred a repository on 13/5/25
ngxson/smolvlm-realtime-webcam (HTML) 3.2k STARS
In fact, convolution neural networks work quite well with images, because in the worst case, you can cut the image to a certain size. For example, creating a model to recognize handwritten digits (MNIST dataset) is one of the very typical and easy-to-experiment exercises for newcomers to machine learning.
Here are the details of a specific commit from the mlfoundations/open_clip repository:
FYI: Looks good to me anecdotally:
Visit the full article: Don't use raw embeddings | Posts · 16/4/2025 · 3 minuteHowever, embeddings are still quite large. OpenAI's text-embedding-3-large can reach up to d=3072, which means 6kB (stored as float32) per entity. From experience, this is enough to overwhelm SQL engines when performing large JOINs, as this data needs to be sent across the network for a distributed JOIN.
gmittal Gautam Mittal
126 repositories226 followers
Gautam Mittal (https://github.com/gmittal) has a repository
skypilot-org/skypilot (Python) 8.2k STARS
Artin Ghasivand(https://github.com/Ei30metry) followed a GitHub user on 27/6/24
https://github.com/chrisdone
Martin Krasser(https://github.com/krasserm) starred a repository on 26/3/25
wjayesh/mahilo (Python) 360 STARS
Alexandre Mutel (https://github.com/xoofx) followed a GitHub user on 2/5/25
meziantou
Just re-illustrating the example from the Russell book Chapter 21. Note how the unit “numbers” have changed. Give it a shot if you have literally nothing else to do. There is a reason we make computers do this.
Visit the Wikipedia Page: Artificial Intelligence: A Modern Approach | Written by Stuart J. Russell and Peter NorvigAIMA has been called "the most popular artificial intelligence textbook in the world",[2] and is considered the standard text in the field of AI.[3][4] As of 2023, it was being used at over 1500 universities worldwide,[5] and it has over 59,000 citations on Google Scholar.[6]

Here are the details of a specific PR from the pytorch/pytorch repository:
Asankhaya Sharma(https://github.com/codelion)
codelion launched their sponsorship page 💖 Asankhaya Sharma codelion on 10/6/25
Asankhaya Sharma(https://github.com/codelion) Trending repositories on 23/5/25
codelion/openevolve (Python) 2.3k STARS
Anthony Shaw(https://github.com/tonybaloney) Created a pull request on 2/6/25
langchain-ai/langchain-community/pull/88
Here are the details of a specific PR from the langchain-ai/langchain-community repository:
Visit the full article: An Introduction to Ibis for Python Programmers | A More Pythonic Way To Work With Databases | Posts · 14/3/2022 · Python, Databases · 10 minutesAnthony Shaw(https://github.com/tonybaloney) contributed to
Azure-Samples/eShopLite on 31/5/25
Anthony Shaw(https://github.com/tonybaloney) contributed to
langchain-ai/langchain-azure - langchain-ai/langchain-azure/pull/99 on 10/6/25
Here are the details of a specific PR from the langchain-ai/langchain-azure repository:
MD5 and SHA1 should never be used for cache keys because there is a chance of collisions.
The implication here is that the in-process cache dictionary will use different cache keys, but that doesn't matter since it's stored in memory and you need to restart to run this update.
Jirka Borovec(https://github.com/Borda) contributed to
Lightning-AI/lightning-thunder/ on 10/6/25
Here are the details of a specific PR from the Lightning-AI/lightning-thunder/pull/2208 repository:
Jirka Borovec(https://github.com/Borda) contributed to
Lightning-AI/lightning-thunder/ on 10/6/25
Here are the details of a specific PR from the Lightning-AI/lightning-thunder/pull/2208 repository:
Anthony Shaw(https://github.com/tonybaloney) contributed to
Azure-Samples/eShopLite on 31/5/25
Alexandre Mutel (https://github.com/xoofx) followed Friedrich von Never (https://github.com/ForNeVeR) on 21/2/25.
Matt DesLauriers (https://github.com/mattdesl) starred a repository on 17/6/25
https://github.com/mattdesl/canvas-dimensions (JavaScript ) 32 STARS
Passionate about technology, I am particularly committed to training myself and understanding new development best practices. From web to software, including mobile applications and IoT, I put my skills to the service of innovation, but also of transmission by giving courses at CESI in Dijon, Lille, and Nancy, and by sharing my knowledge with my colleagues whenever possible.
Alexandre Mutel (https://github.com/xoofx) starred a repository on 20/6/25
JimmyLefevre/kb (C) 275 STARS
kb_text_shape.h provides ICU-like text segmentation (i.e. breaking Unicode text by direction, line, word and grapheme). It also provides Harfbuzz-like text shaping for OpenType fonts, which means it is capable of handling complex script layout and ligatures, among other things.
Wes Doyle(@wesdoyle) (https://github.com/wesdoyle) followed a GitHub user on 4/1/24
roji

Queryable collections?
When "UTC everywhere" isn't enough
When "UTC everywhere" isn't enough In the upcoming version 6.0 of the Npgsql PostgreSQL driver for .NET, we implemented what I think of as "raw mode" (#3852). In a nutshell, this means that you can now use Npgsql without it doing anything to the SQL you provide it - it will simply send your queries as-is to PostgreSQL, without parsing or rewriting them in any way
Anshuman Mishra(@kanpuriyanawab) (https://github.com/kanpuriyanawab?tab=following) follows a GitHub user
Tania Allard(@trallard)
Yoshifumi Kawai(@neuecc) (https://github.com/neuecc?tab=following) follows a GitHub user
Ben (chmark) Adams(@benaadams)
Ben "chmark" Adams ⟠ (@ben_a_adams) repostedShay Rojansky (@shayrojansky) · June 20, 2025 · Reposted after 12/6/25
View the post: Just gave a talk about the new .NET abstraction for vector databases — Microsoft.Extensions.VectorData · Originally posted June 20, 2025 · Reposted by @ben_a_adams between May 26, 2025 and Jun 2, 2025 · .NET, Vector DBs, Data AbstractionsBen "chmark" Adams ⟠ (@ben_a_adams) repostedJimBobSquarePants (@James_M_South) · May 30, 2025 · Reposted between 26/5/25 and 2/6/25
View the post: The ImageSharp codebase is rapidly becoming an excellent reference source for people wanting to utilize cross platform #dotnet intrinsics as I work on improving the performance on mobile. · Originally posted May 30, 2025 · Reposted by @ben_a_adams between May 26, 2025 and Jun 2, 2025 · .NET, #dotnet intrinsics, #ossView the post: ImageSharp has over 43.5 million Nuget downloads and only 37 open issues in the issue tracker (soon to be 36). I'm pretty proud of the quality of the software. 😇. · Originally posted Jan 23, 2023 · .NET, #dotnet intrinsics, #ossScooletz (https://disqus.com/by/scooletz/) commented on 18/1/15
Visit the full article: A fast and efficient implementation of a MemoryPool<T> | Posts · 13/1/2015 · 5 minutesBenchmarks of approximate nearest neighbor libraries in Python
ann-benchmarks.comUse the proper squashing/activation function to calc probabilities for image-classification pipeline.
Currently 'sigmoid' is used for models with the single-label problem type. This is not correct.